
- Volt Active Data v7.0 delivers predictable performance, 24×7, through operational events, while transactionally processing streams of data at high rates.
- v7.0 includes multi-datacenter database replication (XDCR), improved support for real-time analytics via materialized views based on table joins, continuous queries over streams of data, and improvements in high availability (HA).
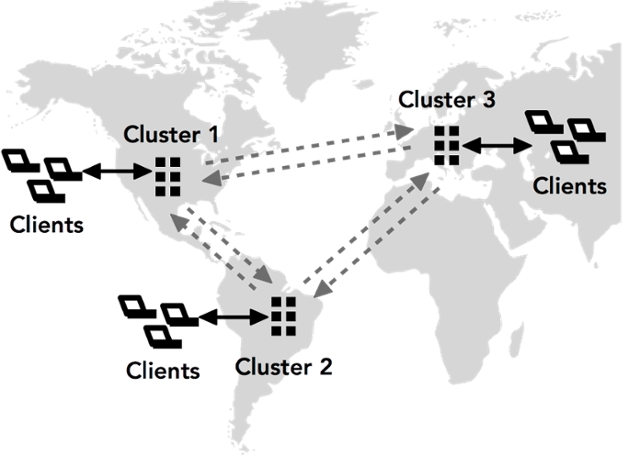
- Volt Active Data Database Replication now allows you to operate active copies of the database in three (3) or more locations.
- Volt Active Data v7.0 supports materialized views on joins of multiple tables, enabling continuous queries over streams of data.
- Volt Active Data v7.0 provides a set of SNMP traps allowing tight integration into existing monitoring systems for Communications Service Providers (CSP).
TL;DR
The Volt Active Data engineering team spent the past 12 months improving and extending our innovative database offering across all facets of the product. Now that we’ve turned the calendar to 2017, we’re ready to introduce you to our newest version of the fastest in-memory SQL operational database, Volt Active Data v7.0.
Volt Active Data v7.0 delivers predictable performance, 24×7, through operational events, all while transactionally processing streams of data at high rates. With v7.0 we’ve added new ways to stream data into Volt Active Data as well as improved the ability to interact with Volt Active Data, via new analytical SQL support. Additionally, we’ve made numerous improvements to the Volt Active Data command line to help with deploying Volt Active Data in auto-provisioning and container environments. Read on for more about Volt Active Data v7.0.
Modern Applications and What They Require from A Database
Today, applications – and the infrastructure software that supports them – must be distributed, cloud-ready, highly available, responsive, automated and fast. Modern applications need to be agile, adaptable to fast-changing business models, all while processing thousands to hundreds of thousands of transactions a second in cloud-based applications as well as those hosted in bare metal servers.
In this context, do these application requirements seem familiar?
- Low, predictable latency, one or two milliseconds on average, with a focus on keeping 99.999% of responses occurring within an order of magnitude of the average.
- The ability to make decisions on flows of incoming data on a per-event basis, using historical insight to inform that decision.
- The ability to run globally, deploying geo-distributed active/active databases across regions.
- The ability to ingest and perform real-time analytics on fast moving streams of data, before passing that data through to the data lake.
These are the core requirements of modern Telco/Communication Service Provider (CSP), IoT, Financial, Gaming and Digital Ad Tech applications, in addition to numerous other emerging application domains. Yes, they’re tough requirements to deliver on a 24x7x365 basis, but they are the requirements Volt Active Data customers demand, and which Volt Active Data delivers.
With release v7.0, Volt Active Data strengthens its commitment to each of these requirements. The v7.0 release includes multi-datacenter database replication (XDCR), improved support for real-time analytics via materialized views based on table joins, enabling continuous queries over streams of data, improvements in high availability (HA), telco and IoT monitoring and health alert support in the form of SNMP traps, and numerous other performance improvements. For more details on v7.0, read on. If you’d like to get your hands on it right now, you can download it here.
Multi-region Volt Active Data Cross Datacenter Replication (XDCR)
In the v6.0 release, Volt Active Data introduced active-active, Cross-Datacenter Replication (XDCR), delivering the ability to have two active Volt Active Data databases replicate to each other, with conflict notification and resolution. Throughout the past year, we’ve continued to enhance this offering, adding the ability to replicate between clusters with different node counts or hardware types. We also allow you to replicate between different versions of Volt Active Data, providing the foundation to perform in-service upgrades to Volt Active Data with no maintenance window.
With the v7.0 release, Volt Active Data Database Replication now allows you to operate active copies of the database in three (3) or more locations, making it possible to support low-latency database interactions that otherwise would result in unacceptable latency when the database and the users are geographically separated. XDCR conflict detection and resolution introduced in v6.0 is supported for this new configuration. For more details on conflict resolution in Volt Active Data, please see the Using Volt Active Data chapter on Understanding Conflict Resolution.
Continuous Queries over Streams (Materialized Views over Table Joins)
Materialized Views form the foundation of real-time analytics in Volt Active Data. Use Materialized Views to define continuous queries on fast-changing data. Continuous queries will avoid costly from-scratch computation and use the cached (pre-computed) result for fast and scalable, response. Volt Active Data supports materialized views on individual tables or streams, and, new with the release of Volt Active Data v7.0, joins of multiple tables. The maintenance of materialized views is transparent, not requiring any configuration and tuning from the user. See the sample below.
CREATE VIEW V (REGION_ID, RECORD_COUNT) AS
SELECT REGIONS.REGION_ID,
COUNT(*) FROM REGIONS JOIN TAXI_LOCATIONS ON
CONTAINS(REGIONS.REGION_BOUNDARY, TAXI_LOCATIONS.TAXI_LOCATION)
GROUP BY REGIONS.REGION_ID;
For an in-depth look at this powerful new capability, please take a look at Ethan Zhang’s blog on continuous queries with joins.
SQL Window Functions
Window functions allow you to perform more selective calculations on statement results than you can do with plain aggregation functions such as COUNT() or SUM(). Window functions execute the specified operation on a subset, a window if you will, of the total selection results, controlled by the PARTITION BY and ORDER BY clauses. This capability is also helpful when computing real-time analytics over streams of data, perhaps moving time windows of data.
Volt Active Data v7.0 supports RANK, DENSE RANK, MIN, MAX, COUNT, and SUM as window functions. By way of a simple example, the voter sample has been simplified to make use of RANK when computing which contestant is ranked 1st (winning) in votes in each U.S. state:
SELECT state, contestant_number, num_votes
FROM ( SELECT state, contestant_number, num_votes,
RANK() OVER ( PARTITION by state
ORDER BY num_votes DESC ) AS vrank
FROM v_votes_by_contestant_number_state ) AS sub
WHERE sub.vrank = 1;
Increased High Availability
Volt Active Data is a distributed database designed to provide the highest levels of consistency and correctness in the face of many kinds of machine and network failures. Last summer we worked with Kyle Kingsbury to externally validate Volt Active Data’s resiliency under the brutal “Jepsen Test”.
In Volt Active Data 7.0, we’ve made changes to the way we replicate data and assign data to individual machines in a cluster to make Volt Active Data even more robust. Without impacting performance or correctness, Volt Active Data clusters with more than three nodes can now survive additional failures without losing availability or using more memory. The differences become even more stark as cluster size increases.
The bottom line for users is that your clusters will have less downtime without any configuration changes. Users who have chosen to run with triple redundancy on larger clusters may find they can achieve nearly the same level of fault-tolerance with single redundancy under the new scheme. And Volt Active Data 7.0 still fully passes Kingsbury’s Jepsen tests (read further for Jepsen details).
SNMP Alerts
When you call someone on your cell, there’s a good chance a Volt Active Data application is approving the call – Volt Active Data is the operational database used by Communications Service Providers (CSP) around the globe. The health of many of these CSP systems is monitored with established SNMP monitoring and alerting systems. With v7.0, Volt Active Data provides a set of SNMP traps allowing tight integration into these systems. For a complete list of traps now supported by Volt Active Data, please see the Volt Active Data Administration Guide Monitoring chapter.
In addition to SNMP, Volt Active Data can be monitored by Nagios and New Relic, via our REST API, and also through the Volt Active Data Management Center (VMC).
Additional Integrations
Volt Active Data continued to expand its integrations over the past year. We now integrate with the AWS Kinesis Firehose through a new Kinesis importer and exporter. For an overview of this new capability, check out Peter Shaw’s summary here: https://www.voltactivedata.com/blog/connecting-voltdb-to-amazon-kinesis-streams
Though we’ve had a Kafka importer and exporter in the Volt Active Data product for quite a while now, we recently added support for loading data from Kafka to Volt Active Data by using the newly released Kafka Connect framework. Our new Volt Active Data Kafka Sink Connector has been certified by Confluent, the commercial entity that supports Kafka. You can find this Connector in our Github repository.
In the “You May Have Missed It” Department …
The Jepsen Test is a very important test in the field of distributed data stores. Jepsen, created and administered by “Breaker of Databases” Kyle Kingsbury, tests and validates (or invalidates as the case may be) the documented guarantees a database makes in the face of various failure modes, such as node failures, network partitions, etc. In the first half of 2016 Volt Active Data commissioned and worked closely with Kyle to run Volt Active Data through Jepsen. Issues were found, issues were fixed and Volt Active Data became a better product for this effort. As a result, we now run a rigorous Jepsen test suite nightly as part of our system tests. Check out the full set of vendor Jepsen tests here: https://aphyr.com/tags/jepsen. You can read Kyle’s findings on Volt Active Data here: https://aphyr.com/posts/331-jepsen-voltdb-6-3, as well as Volt Active Data’s summary of this effort here: https://www.voltactivedata.com/jepsen.
Download Volt Active Data v7.0
To sum up, we’ve spent the past year enhancing Volt Active Data to become more available geographically, and also in the face of failures of all types. Volt Active Data v7.0 delivers predictable performance, 24×7, through operational events, all while transactionally processing streams of data at high rates. With v7.0 we’ve added new ways to stream data into Volt Active Data as well as improved the ability to interact with Volt Active Data, via new analytical SQL support. Additionally, we’ve made numerous improvements to the Volt Active Data command line to help with deploying Volt Active Data in auto-provisioning and container environments. I encourage you to take a look at our feature list (“Changes Since the Last Release” chapter) in our release notes to get a full view of the improvements delivered over the past year.
Finally, thanks for reading! Please download Volt Active Data 7.0 at https://voltactivedata.com/try-volt, and give it a try. We’d love your feedback. Feel free to send us a note at info@voltactivedata.com and we’ll be sure respond.
About Author

Featured Resources



