
- The Internet of Things (IoT) is rapidly growing, with projections of 20.8 billion connected devices by 2020 and nearly 5.5 million new things added daily.
- Legacy data management systems struggle to handle the vast inflows of high-velocity data generated by IoT sensors, making data management and value extraction a significant challenge.
- A global electronics manufacturer improved its IoT data management by implementing Volt Active Data, replacing an in-memory grid and streamlining data processing.
- Volt Active Data provided a consolidated ingest point for IoT data, enabled real-time processing, and automated actions, addressing pain points related to data velocity and complexity.
- IoT environments require both big data (data at rest) and fast data (data in motion) solutions, with operational databases playing a crucial role in enabling real-time processing and automated actions.
TL;DR
More than three billion people globally access the Internet via smartphones and other devices such as watches and fitness trackers. This number pales in comparison to the total number of connected devices and sensors in the Internet of Things (IoT) today. Industry analyst firm Gartner puts this figure at 6.4 billion, and projects growth to 20.8 billion devices by 2020, with nearly 5.5 million new things added to the IoT daily. It’s clear the economic value of the IoT lies with the connected machines, devices, and business and industrial systems that make up the sensor-driven IoT.
Data flows from sensors embedded in electric meters that monitor and conserve energy; from sensors in warehouse lighting systems; from sensors embedded in manufacturing systems and assembly-line robots; and from sensors in smart home systems. Each of these sensors generates a fast stream of data. This high-velocity data flows from all over the world, from billions of endpoints, into your infrastructure.
Legacy data management systems are not designed to handle vast inflows of high-velocity data. Thus managing and extracting value from IoT data is a pressing challenge for enterprise architects and developers. Even highly customized roll-your-own architectures lack the consistency, reliability and scalability needed to extract immediate business value from IoT data.
Before & after: an electronics manufacturer use case
To put the question of fast data’s value to businesses into an IoT context, let’s look at two scenarios: before and after, from the point of view of a global electronics manufacturer of IoT-enabled devices.
Before
Before it sought to implement a fast data strategy, the IoT device manufacturer’s data management platform was a ball of string that looked like this:
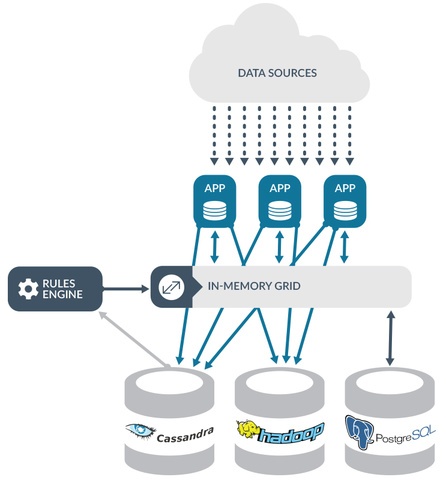
Event data from thousands to millions of devices – some mobile, some ‘smart’, some consumer appliances – arrived via the cloud to be processed by numerous apps, depending on the device type. Sitting between the data sources and the database tier (Cassandra, PostgreSQL and Hadoop) was a rules engine that needed high-speed access to daily event data (e.g., a mobile device subscriber using a smart home app), held in an in-memory data grid used as an intraday cache.
As the rules engine ingested updates from the smart home application, it used the intraday data (e.g., location data on the device) from the in-memory grid to take actions (e.g., turn on lights when the mobile device wasn’t in the home).
The rules engine queried Cassandra directly, creating latency and consistency issues. In some cases, the rules engine required stricter consistency than was guaranteed by Cassandra, for example to ensure that a rule’s execution was idempotent. Scalability issues added to the problem – the rules engine couldn’t push more sophisticated product kits to Cassandra fast enough.
The architecture included PostgreSQL for slow changing dimension data. The in-memory grid cached data from PostgreSQL for use by the rules engine, but the rules engine needed faster access to Cassandra. In addition, each app needed to replicate the incoming event stream to Cassandra and Hadoop.
Further, the scale-out in-memory grid was not capable of functions such as triggering, alerting, or forwarding data to downstream systems. This meant the rules engine and the applications that sat on top of the grid were each responsible for ETL and downstream data push, creating a many-to-many relationship between the ETL or ingest process from the incoming data stream to downstream systems. Each application was responsible for managing its own fault-tolerant ingestion to the long-term repository.
The platform was strangled by the lack of a consolidated ingest strategy; painful many-to-many communications; and performance bottlenecks at the rules engine, which couldn’t get data from Cassandra quickly enough to automate actions. Grid caching was insufficiently fast to process stateful data that required complex logic to execute transactions in the grid, for example the instruction noted before – turn on the lights in the smart home whenever the mobile device is outside the home.
After: Introducing Volt Active Data and fast data
A new, simplified architecture was implemented that replaced the in-memory grid with the Volt Active Data operational database. With Volt Active Data, the rules engine was able to use SQL for more specific, faster queries. Because Volt Active Data is a completely in-memory database, it met the latency and scalability requirements of the rules engine. The database also enabled in-memory aggregations that previously were difficult due to Cassandra’s engineering (e.g., consistency) tradeoffs.
Because Volt Active Data is a relational database, it became the authoritative owner of many of the manufacturer’s master detail records. Master detail records could be associated with intraday events, easing operations and maintaining consistency between inbound data and dimension data (e.g., device id data). Finally, using Volt Active Data export created a unified platform to take the enriched, augmented, filtered and processed intraday event data and push it or replicate it consistently to Cassandra and Hadoop while replicating dimension data changes to the PostgreSQL master detail record system.
Note the simplified architecture in the graphic below.

Adding Volt Active Data to this architecture solved three pain points: it provided a consolidated ingest point for high-velocity feeds of inbound IoT data; it provided processing on inbound data requests that required state, history, or analytic output; and it provided real-time processing of live data, enabling automated actions in response to inbound requests, all with speed that matched the velocity of the inbound data feeds.
In this IoT example, Volt Active Data served not only as a fast intraday in-memory data cache but also as transaction processing engine and a database of record. The bottleneck of reading data from Cassandra was eliminated, as was the n-squared complexity of ingesting and orchestrating many-to-many communications from apps and myriad data sources. An additional benefit was access to analytics that were not previously available from Cassandra due to the sheer volume of processed data.
The role of the operational database in the IoT
The IoT is a very deep stack. It includes devices, security and policy, communication, edge compute and edge analytics. Networks connect the edges to centralized cloud computing infrastructures with data services running in those centralized computing infrastructures. Applications – mostly cloud-based – sit on top.
Two types of data need to be handled in IoT environments: big data, which is data at rest, and fast data, which is data in motion. In this use case, both categories of data have two kinds of applications working on them.
On the big data side, one type of application focuses on data exploration – investigation of large data sets, looking for trends, looking for predictions that can be made, formulating hypotheses with data that can be turned into business value. A second type of application focuses on reporting against that data at rest. These reporting applications might be recommendation matrices or search indices, traditional BI reporting or trend reporting, or perhaps machine-learning models that can be executed in real time.
On the fast data side, the two foundational types of applications written against data in motion are streaming analytics applications and transaction processing applications.
Streaming analytics applications are centered on providing real-time summaries, aggregation, and modeling of data, for example a machine-learning model trained on a big data set or a real-time aggregation and summary of incoming data for real-time dashboarding. These ‘passive’ applications analyze data and derive observations, but don’t support automated decisions or actions.
Transactional applications, on the other hand, take data events as they arrive, add context from big data or analytics – reports generated from the big data side – and enable applications to personalize, authorize, or take action on data on a per-event basis as it arrives – in real-time. These applications require an operational component – a fast, in-memory operational database.
IoT architectural requirements: operational, automated for vast scale and velocity
People are seldom the direct users of operational systems in the IoT – the users are applications. Application requirements in the faster IoT infrastructure happen on a vastly different scale at a vastly different velocity than they do in other systems. The role of managing business data in operational platforms is changing from one in which humans manage data directly by typing queries into an database to one in which machine-to-machine communications and sensors rely on automated responses and actions to meet the scale and velocity challenges of the IoT. IoT apps require an operational database component to provide value by automating actions at machine speed.
IoT platforms such as the one discussed above deliver business value by their ability to process data to make decisions in real time, to archive that data and to enable analytics that can then be turned back into actions that have impact on people, systems, and efficiency.
Look for the next segment of this blog series – Before & After – using Volt Active Data in mobile.
Featured Resources



