
- Kafka Streams is a client library for building applications and microservices that process and analyze data stored in Apache Kafka.
- Kafka Streams faces challenges including not being built for failure recovery due to slow state store restoration, lacking internal consistency which can lead to false outputs, and struggling to scale with complexity, placing resource management burdens on developers.
- Kafka Streams uses state stores and standby replicas for fault tolerance, but lacks a checkpointing mechanism for quick restoration after total system failures, leading to long recovery times.
- Kafka Streams prioritizes eventual consistency, potentially emitting outputs that are temporarily incorrect, and faces challenges in guaranteeing internal consistency despite claims of exactly-once semantics.
- Volt Active Data addresses Kafka Streams’ challenges by providing a streaming database with strong transactional semantics, high availability, and fault tolerance, complementing the Kafka ecosystem and enabling users to capitalize on streaming data without compromising scale, accuracy, or consistency.
TL;DR
We’ve been writing a lot about challenges lately. We recently wrote about API challenges – now we’re discussing challenges with Kafka Streams.
Volt is very big on Kafka, as we specialize in complementing it in a really powerful way to allow enterprises to get the most out of it.
That said, a lot of companies have now started to use Kafka Streams – and, as with any relatively new technology, there are some not-so-negligible growing pains.
Let’s examine what these growing pains are and also look into how to solve them.
But first — let’s define what we’re talking about.
What is Kafka Streams?
Kafka Streams is a client library for building applications and microservices that process and analyze data stored in Apache Kafka. It is an integral part of the Apache Kafka ecosystem, providing a simple and lightweight solution for real-time data processing. Kafka Streams allows developers to perform stream processing tasks directly within their Kafka cluster without requiring any external processing frameworks or tools.
Key features of Kafka Streams include:
Stream processing primitives: Kafka Streams provides a high-level DSL (Domain Specific Language) for defining stream processing operations such as filtering, mapping, aggregating, and joining data streams.
Stateful processing: It supports stateful stream processing, allowing applications to maintain and update state as data streams are processed. This enables operations such as windowed aggregations and sessionization.
Fault tolerance: Kafka Streams is designed to be fault-tolerant and scalable. It leverages Kafka’s built-in features such as replication and partitioning to ensure that data processing is resilient to failures.
Exactly-once processing semantics: Kafka Streams provides support for exactly-once processing semantics, ensuring that each record is processed and produced exactly once, even in the presence of failures.
Integration with Kafka ecosystem: Since Kafka Streams is part of the Apache Kafka ecosystem, it seamlessly integrates with other Kafka components such as Kafka Connect (for data ingestion) and Kafka Producer/Consumer APIs.
Java-based: Kafka Streams is primarily a Java library, but it also has support for other JVM languages like Scala. This makes it easy for Java developers to build and deploy stream processing applications using familiar tools and frameworks.
Overall, Kafka Streams simplifies the development of real-time stream processing applications by providing a lightweight and scalable library that integrates seamlessly with Apache Kafka. It is widely used in various industries for building applications such as real-time analytics, fraud detection, monitoring, and more.
However, Kafka Streams has certain limitations and challenges that real-time data platforms like Volt can address.
Let’s look at the three main challenges with Kafka Streams.
1. Not built for failure recovery
Kafka Streams uses state stores to persist the state of its tasks that are performing stateful stream processing. Stateful operators such as windows and aggregations persist the state of their computation to these state stores before the results are ready to be emitted.
In addition to using state stores, applications can also use standby replicas of these state stores to add redundancy. The standby replicas can increase the high availability of the application by maintaining a hot standby replica that can take over after failure.
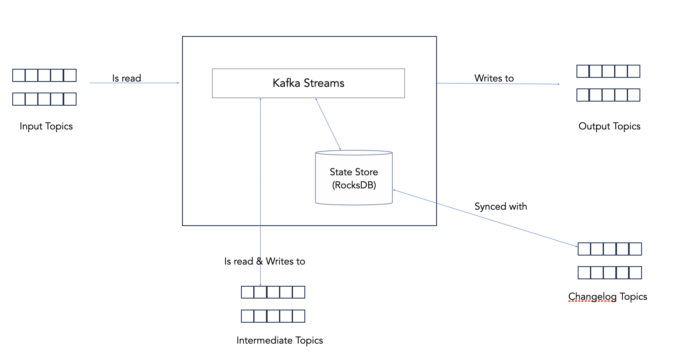
However, in the case of a total system failure, there is no checkpointing mechanism for the state store to quickly restore to its known good state. Kafka Streams uses changelog topics in Kafka which are created and maintained automatically. The only way to restore the state would be to replay the records from the beginning (or from the last known offset which Kafka confusingly calls checkpoints). This approach of durability does not scale with the size of the state store and can lead to restore times of minutes or even hours.
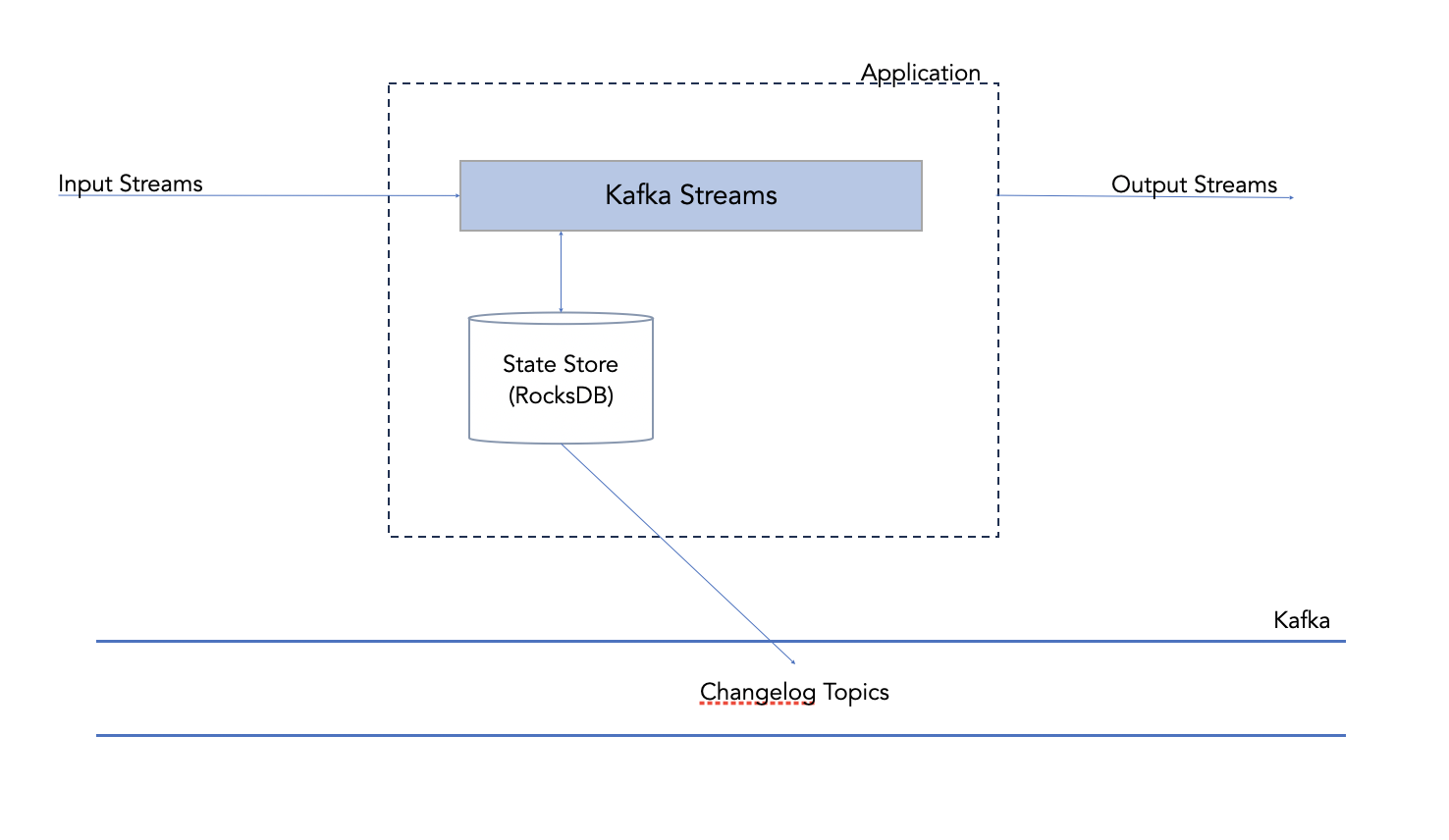
2. Lack of internal consistency
Internal consistency in a stream processing engine is defined as the ability of the system to generate a response that would be correct for at least one subset of the inputs that it has received until then. Kafka Streams is built to eventually provide a result that is consistent with the input but only after the input streams are stopped.
This dependency on eventual consistent processing is perhaps easier to reason about in a database but a stream processing system would be emitting outputs which could always be outright false. Even though Kafka claims support for exactly-once semantics, depth-first processing and transactional event processing, some fundamental challenges prevent Kafka Streams from being able to guarantee internal consistency.
3. Failure to scale with complexity
Since Kafka Streams is a Java library that is embedded into your application to add stream processing capabilities relatively easily. Its tight integration with Kafka allows developers to get started without a steep learning curve.
However, since Kafka Streams is not deployed separately by itself, it becomes the application developer’s responsibility to ensure that the right amount of resources and not less, or more, are allocated to the Kafka Streams. This is necessary to ensure that the application is not affected by any misuse or unexpected use of resources. Unless used for simpler stateless applications, this burden can prove to be a limiting factor in Kafka Streams’ use in implementing complex stream processing. ksqlDB, on the other hand, is deployed stand-alone but does not provide the lower level API for more complex use cases.
“While managing state outside of Kafka Streams is possible, we usually recommend managing state inside Kafka Streams to benefit from high performance and processing guarantees.” – Confluent
RocksDB serves as the state store for Kafka Streams and is a key-value store that supports quick gets and puts. If the processing logic of your application is complex enough to benefit from relational semantics, the use of Kafka Streams will then place the burden of that implementation on your application.
The Volt Advantage for Kafka
The challenges around using Kafka Streams are around the management of state in a fault-tolerant way, which has traditionally been the responsibility of an actual database.
Confluent’s vision of treating Kafka as a database has certainly had issues due to their oversimplification of the underlying concepts and underestimating what it takes to solve them for non-trivial applications. They seem to have acknowledged this, though not explicitly, through their recent acquisition and slowdown of development activity on Kafka Streams.
What, then, are the alternatives?
Streaming databases are built to treat state management as a core challenge of stream processing and make the right choices to ensure correctness and durability guarantees are not compromised regardless of the complexity of the application.
If your application needs high levels of consistency with strong transactional semantics over event streams while providing high availability guarantees, Volt Active Data is a unique technology that brings those together. Built with an in-memory transactional database core to solve challenges in streaming data, Volt has been successfully solving such challenges for applications in telecom, gaming, banking, and media industries, to name a few.
The great thing about Volt is that it lets you either totally prevent or very quickly resolve these Kafka challenges so that you can avoid spending time fixing things or figuring out what to compromise on and focus instead on capitalizing on your streaming data.
Volt was built from the ground up to complement the Kafka ecosystem and fill a key gap in it by allowing you to fully capitalize on your streaming data without compromising on scale, accuracy, or consistency. That’s huge.
With Volt, you can stream all of your events directly to the data platform without hassle, have similar scalability as Kafka with the use of partitioning, and get consistency and global aggregation out-of-the-box if you use Volt’s materialized views, which maintain running totals without excessive overhead or significant developer effort.
Also:
- Volt is built to be fault-tolerant and to recover from failures with minimal service disruption.
- Volt uses synchronous replication to maintain high availability and a combination of command logs and snapshots for quick recovery from failure.
- Volt is a turnkey, off-the-shelf, out-of-the-box Kafka solution to ensure you are getting the most out of Kafka and your streaming data.
It’s the answer to Kafka’s challenges and the only data platform that enables you to fully capitalize on the Kafka opportunity.
INTERESTED IN LEARNING MORE ABOUT GETTING THE MOST OUT OF KAFKA STREAMS? SCHEDULE A CALL WITH A KAFKA STREAMS EXPERT AT VOLT ACTIVE DATA TODAY.

About Author


Featured Resources



