
- The voltdb-chargingdemo demonstrates how Volt Active Data can be used in scenarios where users are working with shared and finite resources while meeting SLAs, such as in telco charging systems.
- The demo is designed to be realistic, representing a simplified version of a ‘charging’ system used by prepaid cell phones, which manages user provisioning, credit additions, and usage reporting.
- The system addresses challenges such as handling multiple products, factoring in reserved balances, performing sanity checks, ensuring high availability (though not fully implemented in the demo), managing downstream systems, and calculating value at risk.
- The demo supports multiple devices and sessions sharing a balance, requiring system-generated unique session identifiers to prevent duplicate spending.
- The system is designed to meet latency expectations (5-10ms per request) and scale to handle a high transaction rate (166,666 transactions per second), simulating a busy hour spike on New Year’s Eve with 20,000,000 users.
TL;DR
Introduction
In this post I’d like to highlight voltdb-chargingdemo, which I’ve recently made available on github. Most demos are designed to be as simplistic as possible. I’ve always found that frustrating, as anyone who has ever written a real world application knows that what takes two lines in a demo can take about 50 in reality. With that in mind, I wrote voltdb-chargingdemo, which is intended to demonstrate how we can help in scenarios such as telco where users are working with shared and finite resources while meeting SLAs, such as SMS messages or bandwidth. Instead of simplifying things to the point of absurdity, it tries to be realistic yet still comprehensible to outsiders.
My own background is in telco, and the demo is a drastically simplified representation of what’s known as a ‘charging’ system. Every prepaid cell phone uses one of these – it decides what the user can do, how long they can do it for, and tells downstream systems what was used when the activity finishes. In such a system the following activities happen:
- “Provision” a user. This happens once, and is the part where they enter the number on your sim card into the computer at the store so the phone systems knows that that sim card is now 1-510-555-1212 or whatever your number is.
- “Add Credit”. This is when a third party system tells the phone company’s computer that you have just gone to a recharging center and added US$20 in credit.
- “Report Usage and Reserve More”. In real life this is several steps, but to keep things simple we use one. In this the phone system tells Volt Active Data how much of a resource you’ve used (“Usage”), and how much they think you’ll need over the next 30 seconds or so (“Reserve”). Normal practice is to hand over a larger chunk than we think you’ll need, as if you run out we may have to freeze your ability to call or internet activity, depending on your usage, until we get more. For a given user this is happening about once every 30 seconds, for each activity.
The Challenges
All of this seems simple, but then we have to consider various other ‘real world’ factors:
Products
Our demo phone company has 4 products. As in real life, a user can use more than one at once:
| Product | Unit Cost |
| The phone company’s web site. Customers can always access the phone company’s web site, even if they are out of money. | 0 |
| SMS messages, per message. | 1c |
| Domestic Internet Access per GB | 20c |
| Roaming Internet Access per GB | $3.42 |
| Domestic calls per minute | 3c |
This means that when serving requests we need to turn the incoming request for ‘access per GB’ into real money and compare it to the user’s balance when deciding how much access to grant .
We have to factor in reserved balances when making decisions
We shouldn’t let you spend money you haven’t got, so your usable balance has to take into account what you’ve reserved. Note that any credit you’ve reserved affects your balance immediately, so your balance can sometimes spike up slightly if you reserve 800 units and then come back reporting usage of 200.
Sanity Checks
Like any real world production code we need to be sure that the users and products we’re talking about are real, and that somebody hasn’t accidentally changed the order of the parameters being sent to the system.
High Availability
Although this demo doesn’t include support for failovers (I’m working on a HA/XDCR demo) the schema does. In any HA scenario you have to cope with a situation where you send a request to the database and then don’t know whether it worked or not, as you didn’t get a message back. Given that when we report usage we’re spending customer’s money we can never, ever get into a situation where we charge them twice. This means that each call to “Add Credit” or “Report Usage and Reserve More” needs to include a unique identifier for the transaction, and the system needs to keep a list of successful transactions for long enough to make sure it’s not a duplicate.
Downstream Systems
In addition to allowing or denying access we need to tell a downstream back office system when money is spent or added. This needs to be accurate and up to date. In our demo we implement this using an Export Stream called ‘user_financial_events’, which goes to a logical destination called ‘finevent’. ‘Finevent’ can be Kafka, Kinesis, JDBC, etc.
Value at Risk calculations
We need to know:
- What is the total amount of credit we are holding in this system?
- How much is currently being reserved for each product?
This needs to be checked every few seconds without causing disruption. This is a classic HTAP/Translytics use case.
Multiple Devices & Sessions
Although we don’t show it in the demo, the schema and code support multiple devices sharing a balance. In the real world we see this in ‘friends and family’ plans. This means that knowing you are user #42 and want to report usage for product #3 isn’t enough, as two or more devices could be doing this at the same time. We thus have a requirement for system generated unique session identifiers.
More importantly we can never tolerate a situation where two devices on the same plan spend the same money twice!
Latency Expectations
The phone company’s server has about 50ms (1/20th of a second) to decide what to do when a request shows up. Because we’re only a small part of this decision making process, we can only spend between 5-10ms per request. Note that we need to be consistently fast. An average latency of 7ms is no good if the ‘99th percentile’ latency is 72ms.
Scale Expectations
It’s not unusual for 20,000,000 users to be on one of these systems. In this demo we design for a busy hour spike on New Year’s eve where 25% of customers are active at the same moment. This implies 5,000,000 active devices, each creating a “Report Usage and Reserve More” request every 30 seconds. 5,000,000 / 30 = 166,666 transactions per second, which is our design goal.
Note that in Use Cases where latency spikes are OK, scaling is usually a lot easier.
Arbitrary Payload
We also sometimes have to store device session data, which is presented to us as a JSON object. While the code allows you to read, softlock and update this JSON it isn’t currently part of the demo.
Our Schema
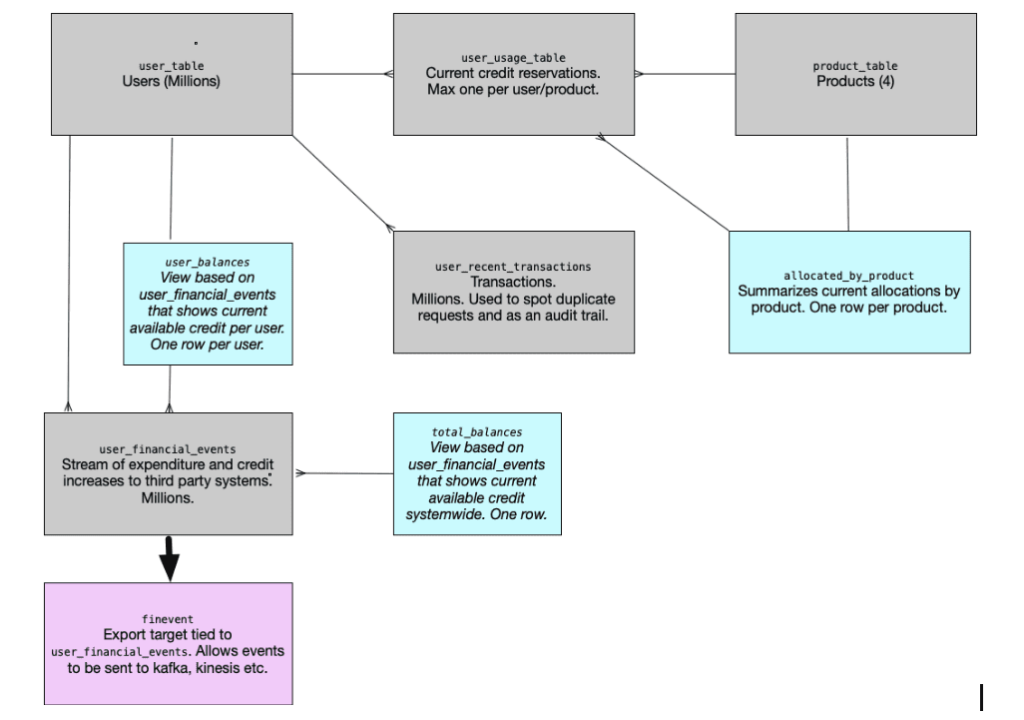
| Name | Type | Purpose | Partitioning |
| user_table | Table | Holds one record per user and the JSON payload. | userid |
| Product_table | Table | Holds one record per product | |
| User_usage_table | Table | Holds information on active reservations of credit by a user for a product. | userid |
| User_balances | View | It has one row per user and always contains the user’s current credit, before we allow for reservations in “user_usage_table”. | userid |
| User_recent_transactions | Table | Allows us to spot duplicate transactions and also allows us to track what happened to a specific user during a run | userid |
| allocated_by_product | View | How much of each product is currently reserved | |
| total_balances | View | A single row listing how much credit the system holds. | |
| User_financial_events | Export stream | Inserted into when we add or spend money | userid |
| finevent | Export target | Where rows in user_financial_events end up – could be kafka, kinesis, HDFS etc | userid |
How to run the demo
Prerequisites
In the example below we assume we have access to a 4 node AWS cluster based on Ubuntu.
We used a cluster with the following configuration:
- 4 x AWS z1d.3xlarge nodes (1 client, 3 for the server)
- Command Logs and Snapshots on internal SSD drive
- K factor of ‘1’.
- Default settings for command log flush interval.
- Sitesperhost set to default value of 8.
- 20,000,000 users
- Use the script runtest.sh to run 5 instances at the same time
Goal
- Run 166,666 or more transactions per second.
- 99th percentile latency needs to be 10ms or under.
- The transactions will be 80% “Report Usage and Reserve More” and 20% “Add Credit”
- We will also call “showCurrentAllocations” and “getTotalBalance” every 10 seconds.
Steps
- Obtain Volt Active Data
Volt Active Data can be downloaded here. - Create your cluster
Instructions for how to do this are here. Alternatively we can give you access to the AWS CloudFormation scripts we used if you contact us. - Obtain the Demo
git clone https://sr_mad_science@bitbucket.org/voltdbseteam/voltdb-chargingdemo.git
- Create the schema
cd voltdb-chargingdemo/ddl sqlcmd --servers=vdb1 < db.sql
Note that this code loads a jar file from voltdb-chargingdemo/jars.
- Run ChargingDemo
ChargingDemo lives in a JAR file called ‘voltdb-chargingdemo-server.jar’ and takes the following parameters:
| Name | Purpose | Example |
| hostnames | Comma delimited list of nodes that make up your VoltDB cluster | vdb1,vdb2,vdb3 |
| recordcount | How many users. | 200000 |
| offset | Used when we want to run multiple copies of ChargingDemo with different users. If recordcount is 2500000 calling a second copy of ChargingDemo with an offset of 3000000 will lead it to creating users in the range 3000000 to 5500000 | 0 |
| tpms | How many transactions per millisecond you want to achieve. Note that a single instance of ChargingDemo will only have a single VoltDB client, which will limit it to around 200 TPMS. To go beyond this you need to run more than one copy. | 83 |
| task | One of: DELETE – deletes users and data USERS – creates users TRANSACTIONS – does testrun Or RUN – Does DELETE, USERS and then TRANSACTIONS | RUN |
| loblength | How long the arbitrary JSON payload is | 10 |
| durationseconds | How long TRANSACTIONS runs for in seconds | 300 |
| queryseconds | How often we query to check allocations and balances in seconds, along with an arbitrary query of a single user. | 10 |
| initialcredit | How much credit users start with. A high value for this will reduce the number of times AddCredit is called. | 1000 |
| addcreditinterval | How often we add credit based on the number of transactions we are doing – a value of ‘6’ means every 6th transaction will be AddCredit. A value of 0 means that AddCredit is only called for a user when ‘initialcredit’ is run down to zero. | 6 |
An invocation of the demo looks like this:
java -jar ../jars/voltdb-chargingdemo-server.jar vdb1,vdb2,vdb3 1000000 1000000 32 TRANSACTIONS 10 300 10 100000 5
To make things easier we use a file called “runtest.sh”, which creates the users and then runs the workload at increasing intervals and puts the results in a file. Note that runtest.sh will need to be tweaked in order for you to use it.
“runtest.sh” can be persuaded to do a series of runs at increasing TPS levels and put the results in a file for later analysis, which is what we did.
Sample Results
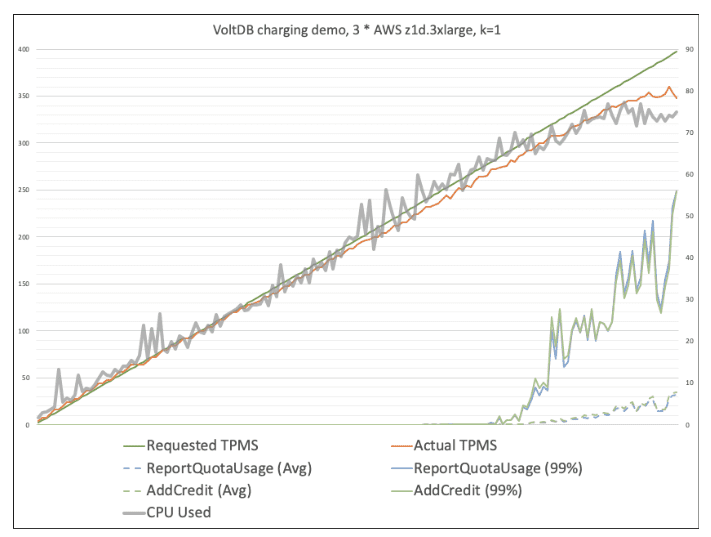
In the graph below the green line is “Requested TPMS” – How many transactions per millisecond we were trying to do.
The red line is what we actually did. Due to the vagaries of how the test runs it’s often slightly higher than “Requested TPMS” at the start, but then tracks it reasonably accurately.
The grey line is server CPU Busy %, which is on the right hand scale. We see that it accurately aligns with “Actual TPMS”, which is good.
The blue line is the 99th Percentile latency for ReportQuotaUsage. This is where we start to see the system hit its limits. Until 272 TPMS it’s 1ms, but then it rapidly spikes to 9ms at 274 TPMS and breaks our SLA at 286 TPMS with 19ms. This is what we’d expect, as the CPU is around 75% by then, and requests are starting to queue, which manifests itself as latency.
The Blue dashed line below is the average latency for ReportQuotaUsage, and shows that if you didn’t care about the 99th percentile and were willing to work with average latency instead, you could probably get around 25% more TPMS out of the system.
The Green lines show us that the profile of AddCredit is pretty much the same.
In practical terms this means we could easily meet the requested workload of 166,666 TPS.
Putting the results in context
Work per CPU
Each z1d.3xlarge provides 6 physical CPU cores, so in a 3 node cluster with k=1 we’re actually using 12 cores, as all the work is being done twice on two servers. At 270K TPS each physical core is therefore processing 22,500 requests per second.
Statements per call
Each request can and does issue multiple SQL statements. For example “Report Usage and Reserve More” issues between 7 and 14 each invocation, so if you want to look at this in terms of “SQL statements per second” the actual capacity is around 2,700,000 operations per second.
Conclusion
In this blog post and accompanying demo I’ve shown that Volt Active Data can be used to build very high performance ACID compliant applications that provide the benefits of a traditional RDBMS and run in a 100% virtualized cloud environment while providing high availability.
About Author

Featured Resources



