
- Working on distributed systems is fun, but not easy, particularly setting up environments, starting processes, and monitoring them on multiple machines.
- Many things can go wrong when setting up the environment, such as stale settings, incorrect configurations, or file collisions.
- Docker simplifies the development and testing of distributed systems by providing container isolation, making it easier to start a cluster of nodes on a single machine.
- Using Docker allows for simulating node failures and rejoining new nodes into the cluster, enhancing the ability to test highly available systems.
- Docker, combined with tools like nsenter, simplifies debugging by allowing developers to step into running containers, inspect processes, and collect logs from a shared directory.
TL;DR
Working on distributed systems is fun, but not easy! As a software engineer at Volt Active Data, a big chunk of my time is spent testing software on a cluster of machines as part of new feature development and also for customer issue reproduction. Any software engineer who does this on a daily basis knows this is not an easy process.
Volt Active Data is a clustered database. A big part of the challenge building Volt Active Data features comes from the fact that database processing is distributed, involving multiple processes on different machines connected by a network. In this blog post I’ll focus specifically on how developers can simplify the development and testing of a distributed system like Volt Active Data.
Setting up environments, starting processes, and monitoring these processes on multiple machines is still painful and error prone, even with tools like tmux. When setting up the environment there are a lot of things that could go wrong; for example, stale settings left from previous tests, incorrect configuration on some of the machines, executing the wrong command on some portion of the machines, using local file systems when you need them to be shared, or file collision on shared file systems when you need them to be separate, etc. The opportunities for mistakes goes on and on!
Certainly a lot of these common pitfalls can be minimized by scripting. However, this is more true for production/ops, and less so for development. When I work on features or bugs, I usually need to tweak settings or commands from run to run. Sometimes I put one-off configurations in the program to be able to tweak behavior on the fly. With this type of iterative development I cannot easily write a script and reuse it time after time.
Once debugging goes beyond simple log reading, I need to be able to print stack traces of certain processes or dump their heaps and collect all the artifacts. Again, it’s not a trivial task when dealing with multiple machines.
Here’s where Docker makes life much easier: I built a very simple Docker image that has the common tools I need to run and debug Volt Active Data. With the isolation of the container, I can easily start a cluster of Volt Active Data nodes on a single physical machine, which eliminates most of the difficulties mentioned above. Let me give you a concrete example of how I use it.
I am working on database replication, which requires minimally two clusters to be up at the same time. In the dark ages, to run a simple test after code change, I had to build the product, copy the binaries over SSH to all remote machines, SSH into each machine and make sure they had the same configuration, then start the database process on each one of them. Since the two clusters had slightly different configurations, I had to do this whole process on two different sets of machines.
With Docker, all I have to do is to start the containers with the same Volt Active Data package which has the latest binaries and configuration for each cluster. The run.sh script I use below can be found here.
| $ PREFIX=”boston” HOSTCOUNT=2 VOLTPATH=”boston” ./run.sh start | |
| $ DOCKER_ENV=”$DOCKER_ENV –link boston1:boston1″ VOLT_ARGS=”-r” PREFIX=”tokyo” HOSTCOUNT=2 VOLTPATH=”tokyo” ./run.sh start |
view rawDocker Distributed Systems1 hosted with ❤ by GitHub
The commands above start a cluster named boston with two Volt Active Data nodes, and a cluster named tokyo with two Volt Active Data nodes. The nodes in the tokyo cluster can talk to the nodes in the boston cluster because the containers are linked together.
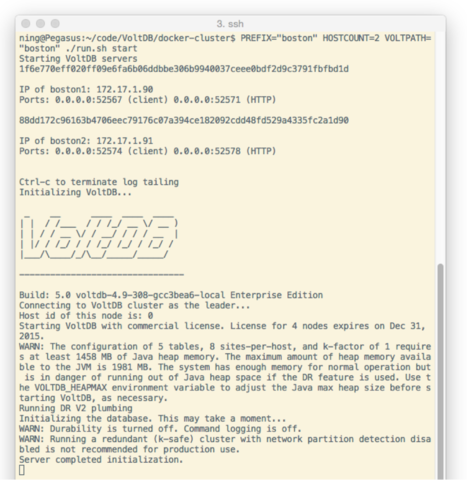
Figure 1: Starting the boston cluster
Even though all the Volt Active Data processes listen on the same set of ports, they won’t collide running on my desktop because each one runs in its own container. All ports are exposed to the host machine on a different port so I can connect to them easily from outside the containers. To find out which host port the Volt Active Data client port is mapped to for one of the servers in the boston cluster, I write a simple command:
| $ docker port boston1 21212 | |
| 0.0.0.0:52567 |
view rawDocker Distributed Systems2 hosted with ❤ by GitHub
Then I can start a client to generate load in the host machine by telling it to connect to port 52567 on localhost.
| $ client.sh –host=”localhost:52567” |
view rawDocker Distributed Systems3 hosted with ❤ by GitHub
To simplify this, I can combine the two commands together so I don’t have to copy/paste the port number every time I rerun the test.
| $ client.sh –host=`docker port boston1 21212` |
view rawDocker Distributed Systems4 hosted with ❤ by GitHub
The clusters I started are highly available. I can simulate node failures, terminating one of the two nodes by stopping the Docker container.
| $ docker rm -f boston2 |
view rawDocker Distributed Systems5 hosted with ❤ by GitHub
When I am ready to rejoin a new node back into the boston cluster, I will start a new container.
| $ NAME=”boston2″ VOLTPATH=”boston” LINKS=”boston1″ LEADER_NAME=”boston1″ VOLT_ACTION=”rejoin” ./run.sh startone |
view rawDocker Distributed Systems6 hosted with ❤ by GitHub
Running “docker ps” shows that all four nodes in both clusters are back online.
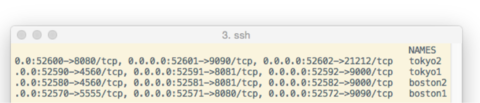
Figure 2: Listing all four containers in two clusters
The run.sh helper script creates containers with a shared directory with the host machine. When the containers start running, that shared directory will be the current working directory. Since I build Volt Active Data binaries into the shared directory, I don’t have to copy them after code change. I also put the deployment file and the catalog.jar file in the shared directory so I can easily change them on the host machine from run to run.
The other benefit of using a shared directory is to collect logs. Log files from all containers are written in to the same directory on the host machine. Simply tailing the file gives me a complete picture of what the whole cluster is doing.
I cannot talk about Docker without mentioning nsenter. It is a tool that allows you to step into a running container and run commands. It is like opening an SSH connection to a remote server.
If I suspect one of the server processes is hung, I use nsenter to get into that container and jstack the process to figure out what each thread is doing.
| $ docker-enter boston1 | |
| root@boston1:/# jps | |
| 111 Jps | |
| 12 Volt Active Data | |
| root@boston1:/# jstack 12 | less |
view rawDocker Distributed Systems7 hosted with ❤ by GitHub
At the end of each test, I shut down all server processes and clean up any artifacts it generated by removing the containers.
| $ docker rm -f $(docker ps -a -q) |
view rawDocker Distributed Systems8 hosted with ❤ by GitHub
Conclusion – Distributed Software Development Simplified
Docker has simplified my distributed system development and debugging process tremendously. The script I use is fairly minimal and will not work for all cases, but as simple as it is, it’s enough to start/stop clusters and stop/rejoin specific server node(s). I can customize the command to use and pass any environment variables into the containers for each test without much effort.
If you find it useful and would like to contribute to make the script more powerful, I am happy to take pull requests.
We also built a Docker image that has Volt Active Data pre-installed with sample applications. You can find it here.
Github repository: https://github.com/nshi/voltdb-docker-cluster(link is external)
Docker image: https://registry.hub.docker.com/u/nshi/voltdb-docker-cluster/
Featured Resources



