
- Telco operators need applications and data in multiple locations to prevent data loss and must respond to customer requests in milliseconds to maintain loyalty, creating a conflict due to latency.
- Achieving ‘five nines’ availability (99.999% uptime) and physical survivability (data in multiple, geographically separated data centers) is crucial but challenging for telco systems.
- Active-standby configurations in legacy systems have limitations in scale, operational complexity, and difficulty in switching between active and standby sites during disasters.
- Active-active systems address latency but introduce data conflicts, where the same resource can be used twice, leading to inconsistencies that traditional data platforms manage inadequately.
- Volt Active Data’s Active(N) Lossless XDCR resolves conflict resolution issues at the application level, preventing data loss while maintaining low latency by using timestamp-based reconciliation and informing the application of conflict resolutions via Kafka.
TL;DR
Today’s telco operators have two key needs: the need for their applications and data need to be in multiple physical locations at once to prevent data loss, and the need to respond within single-digit milliseconds to customer requests in order to maintain customer loyalty.
But since geographic separation causes latency, there’s an inherent conflict in this scenario.
This article explains how operators can mitigate this conflict using a new, Volt Active Data-invented form of cross data center replication (XDCR) that prevents data loss while still allowing for low-latency running of telco networks across widely distributed locations.
The challenge of achieving both ‘five nines’ availability and low latency
It’s now well-accepted in the telecommunications industry that telco systems supporting mission-critical functions such as charging or policy need to provide ‘five nines’ of availability—i.e. 99.999% uptime, which equates to around five minutes of unscheduled downtime a year.
There’s also a requirement for ‘physical survivability’, which means the application and its data need to run in more than one data center at once, and these data centers need to be several miles apart so that they can’t both be destroyed by the same catastrophic event.
However, using data that lives in more than one location has always been a technical challenge. Legacy relational database management systems could potentially offer an active-standby configuration, where all the traffic is sent to one data center and the changes are drip-fed to a backup data center. These deployments can work but are limited in scale and almost unlimited in operational complexity and software licensing costs.
In particular, the process for making the “standby” site “active” and vice versa while the overall telco network continues to operate is a tricky manual process that is hard to do well under plausible real-world disaster scenarios.
Let’s look at an example of why active/standby is problematic:
- Alice is in charge of the ‘active’ data center in San Francisco.
- Bob is in charge of the pPassive’ data center in Los Angeles.
- There are vague reports of an earthquake near the town of King City, CA, which is located between San Francisco and Los Angeles.
- Bob notices that he is no longer receiving changes from Los Angeles, and can’t contact Alice.
What can Bob do?
- If he makes his site active and Alice’s site is still active, he’ll break everything.
- If he waits for connectivity to come back, then his data center can’t serve customers.
It’s a Catch 22 scenario – if he has the information he needs to reliably switch from Standby to Active then there is no need to do the switch…
Meanwhile, outside King City a backhoe driver is trying to make a phone call about a surprise cable he just found, but keeps getting busy signals…
The active/standby configuration also presents other problems:
1. Two data centers is not enough.
The ‘five nines’ goal applies to unscheduled downtime.
Scheduled downtime is another matter. While application vendors can devote engineering time to minimizing downtime during upgrades, they have no ability to influence anybody in the stack underneath them, so activities such as operating system upgrades and security patches will take as long as they are going to take. Hardware changes can also take an open-ended amount of time.
Our customers work on the assumption that scheduled downtime can take weeks. As a result, they need to have the system in three data centers, because at various times only two will be in use.
While an active/standby/standby configuration that covers three data centers is possible, it leads to even bigger human and financial overheads and introduces new risks and exciting modes of failure.
2. Achieving low application latency requires a nearby active data center.
Operators in large markets need to maintain industry standard SLAs of a few milliseconds, even if their customers are sharing balances and are thousands of miles from their home market.
But 5G has aggressive latency requirements that make it physically impossible to serve a market like the US from a single data center in (say) Omaha, Nebraska. Thus, you need a lot of active data centers if you want to meet a 5-millisecond SLA that is now constrained by the speed of light’s limit of 186 miles per millisecond.
Edge computing revolves around the premise of ultra-low latencies, and while there’s a lot of industry enthusiasm for putting applications in close proximity to users and even inside their domestic DSL routers, very little thought has gone into how this works at a national level.
One thing we can be fairly sure of is that edge devices will ultimately need to communicate with a controlling application that lives in three or more data centers.
Data conflicts are unavoidable in an active-active system
Newer data platforms make active-active XDCR much easier. But once you deploy an active-active system, you need to address conflicts.
Conflicts will happen because if you have data centers in (say) Los Angeles and San Francisco, they will have to make decisions by themselves to meet SLAs. This lack of coordination means it’s physically possible for the same last dollar to be spent twice (ie, by two different people), leading to a negative balance.
Most modern data platforms treat this as a data-wrangling issue and use built-in functionality to make sure the data remains consistent over multiple locations. So, if they can do this, why not just write your favorite database vendor a check and let them worry about it? If only it were that simple…
The problem isn’t that these data platforms don’t manage conflicts at all, it’s that they manage conflicts without any regard for secondary consequences. For example, if a seat on a flight is double-booked, the airline can ‘fix’ the problem by deleting one of the bookings, but they still have to deal with the person whose flight they just cancelled.
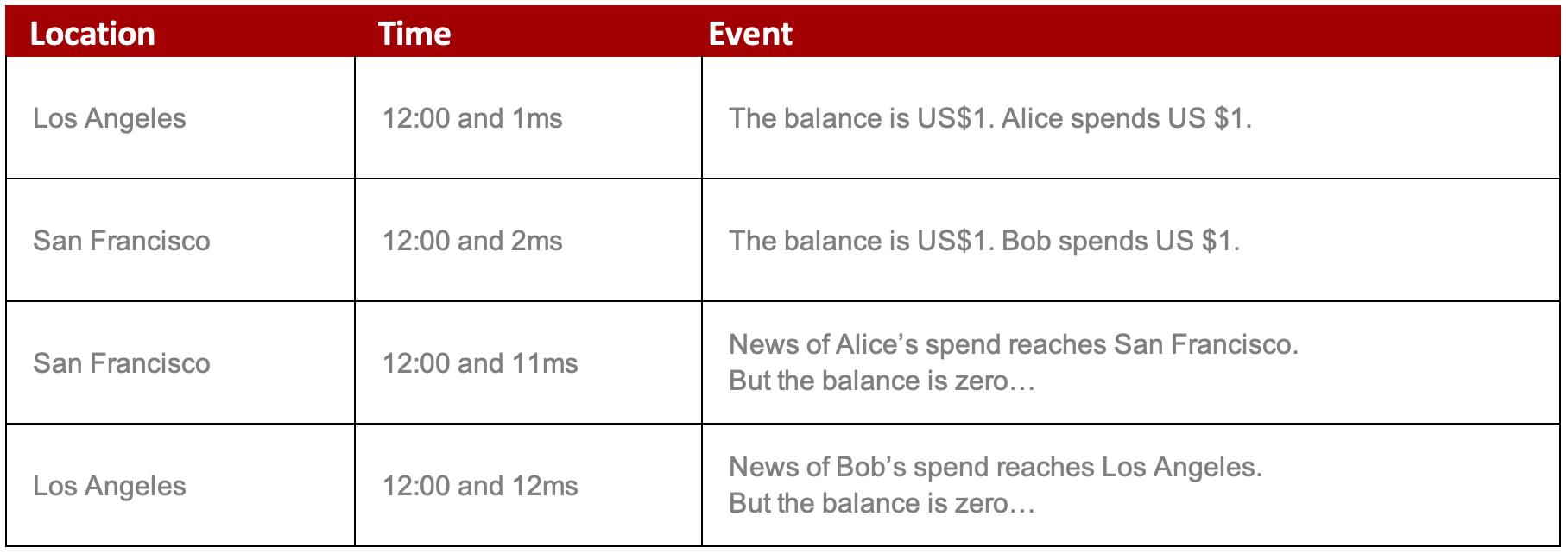
What a conflict looks like:
Modern data platforms employ two strategies to manage conflicts:
The first is called conflict-free replicated data type (CRDT) and involves merging the numerical changes. So in the example above, instead of overwriting the value, both sites would subtract US $1 from the value they have, leading to them both ending up with a negative $1 balance. But this strategy only works for simple numerical events and happens silently so the application doesn’t know about the negative balance until the user tries to use their device again. (Wouldn’t it be nice if it knew so it could make a perfectly timed offer to the user to buy more credit?)
The second strategy is timestamp-based reconciliation and involves looking at timestamps before picking a winner, who is generally the last person to make a change. The loser’s transaction vanishes. In the example above, the balance would end up at zero because the system would ‘forget’ Bob’s transaction.
Either way, money (and very likely, the customer as well) is lost.
Clearly we need a better solution for managing data conflicts in the fast-data age of 5G.
How Volt Active Data’s Active(N) Lossless XDCR makes telco-grade active-active-active practical
Volt Active Data’s Active(N) Lossless XDCR is a new kind of XDCR designed to resolve these critical conflict resolution issues at the application level, allowing enterprise-grade networks to avoid losing data, even in the face of massive data volume, velocity, and variety, while still providing ultra-reliable low latency.
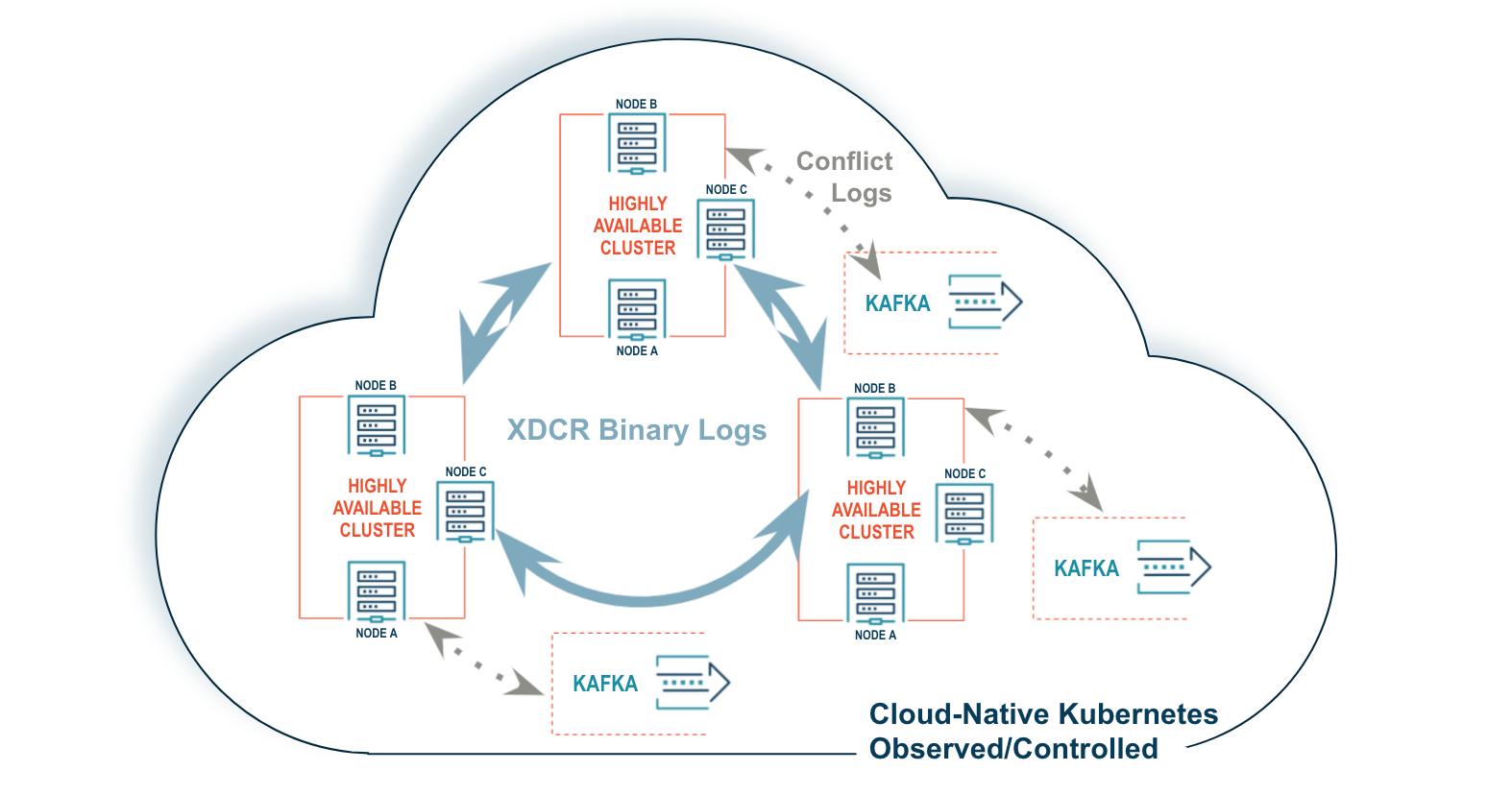
Active(N) uses three (or more) data centers with high-availability clusters and enhanced data observability via Kubernetes to achieve active-active-active XDCR with application-level conflict resolution.
Active (N) Lossless XDCR uses timestamp-based reconciliation but also uses Kafka to tell the application how it resolves each conflict. In the example above, Bob’s transaction would be rejected because it started after Alice’s, but the application would know within a second what’s happened and can make an intelligent business decision about what to do.
In many cases the application can shrug, ignore the situation, and move on, but what if Bob was adding US $100 in credit when his transaction was ‘stepped on’ by Alice? In such a case, the application can resubmit Bob’s US $100 and thus avoid an angry and potentially litigious customer.
Bob’s money is saved, and so is the company’s: a win-win.
In the end, what Active(N) enables is the error-free functioning of enterprise-grade telco networks in the age of 5G, preventing damaging or even disastrous revenue loss and empowering companies to take full advantage of 5G to tap into new revenue streams. It’s a new kind of XDCR, yes, but in fact, it’s much more than that—it’s a business-enabler to unlock incredible new value from enterprise data in an age where there is more enterprise data than ever from which to derive value.
5G IS CHANGING ENTERPRISE NEEDS AROUND LATENCY AND XDCR. READ OUR ACTIVE(N) LOSSLESS CROSS DATA CENTER REPLICATION PAPER TO LEARN HOW VOLT ACTIVE DATA IS REDEFINING WHAT’S POSSIBLE WITH ACTIVE(N) LOSSLESS XDCR.
About Author

Featured Resources



