
- Relational databases have been dominant for 30 years, but are increasingly challenged by new technologies like NoSQL and NewSQL databases, and Hadoop HDFS.
- Scalability refers to options for coping with long-term traffic increases when spare capacity is exhausted, typically through vertical (scale up) or horizontal (scale out) methods.
- System performance (throughput/response time) differs from scalability and is improved through efficient database design, while scalability is built into the hardware architecture.
- Elasticity, associated with cloud solutions, is the ability to rapidly grow or shrink system resources dynamically based on processing demands, offering cost control and efficient resource use.
- Architect for scalability from the start because once the system is selected and installed, your options to scale are already decided. Performance can be designed and tuned later.
TL;DR
Editor’s note: This post is re-posted here by permission from the author. The original post was on LinkedIn on December 2, 2017.Despite multiple challenger technologies (eg. Object Oriented databases), the relational databases from Oracle, IBM and Microsoft have prevailed supreme for over 30 years. This dominance has however been increasingly challenged by a new wave of technology solutions which started with database appliances from Teradata and Nettezza. Driven by Big Data requirements, this was followed by open source NoSQL databases including HBase and Cassandra. Development continued with NewSQL databases including Volt Active Data and MemSQL, and finally in (although not a database), Hadoop HDFS is providing a significant challenge as a potential data store. You must read cloud data platform best practices.
In this article, I will summarize the traditional approaches available to provide database scalability, comparing the benefits and drawbacks of each. In part two, I’ll describe the different database architectures, and in the final article, I’ll describe how the new challenger solutions fit in to the overall picture.
First, it’s sensible to define some terms.
What is Scalability?
Most systems don’t run at 100% capacity, and must build in headroom to allow for a temporary spike in traffic without a significant drop in performance. However, this does not make them scalable, just that there’s spare capacity. Scalability refers to the options available to cope with a longer term increase in traffic when there’s no headroom available. The typical options are described as vertical (scale up), or horizontal (scale out).
Scalability vs Performance
Although closely correlated, it’s important to treat these separately as they often require a different approach. System performance refers to the throughput (transactions per minute) or average response time. In my experience, performance improvements are gained using efficient database design, and scalability during the selection of an appropriate hardware architecture.
In short, you need to build scalability into the hardware architecture and database selection, and can (for the most part), maximise performance later – during the database design and deployment phase. Do this in the wrong sequence, and you’ll find your scalability options severely limited.
What is Elasticity?
Typically associated with Cloud based solutions (either on premises or hosted externally), this refers to the ability of the system to rapidly grow or shrink as the processing demands change – often dynamically. This implies manual or automatic hardware allocation on a cluster to best match the resources available to the demands of a given task. Elasticity (and associated cost control) is one of the greatest benefits of cloud based solutions and can be used to control costs, and make more efficient use of machine resources.
Scalability Options
Assuming you need to scale your system, there are two options, scaling Up or Out.
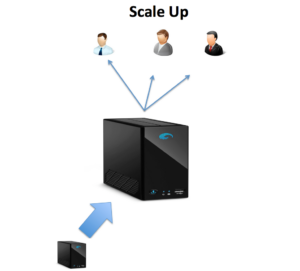
The diagram above illustrates the situation where we add disk, memory or processing capacity to the system, and eventually to migrating to a larger hardware platform. Typically however, neither the benefits nor the costs are linear, and faster disks, processors and network add significant cost. In addition, as most systems are constrained by a performance bottleneck, increasing capacity in one area often shifts the bottleneck to another, and doubling the size of the machine seldom doubles the capacity.
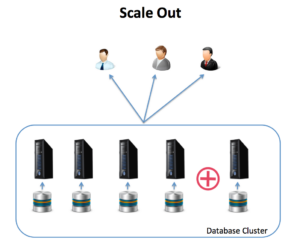
The scale out option implies a distributed system whereby additional machines are added to a cluster to provide additional capacity. Often more likely to yield a linear increase in scalability, although not necessarily increased performance.
The arguments for/against Scaling Up include:
- Ease of extension: As a method of providing additional head-room, adding more memory or faster components can extend the life of existing hardware without the need to re-architect or replace the entire system.
- Relative Hardware Cost: As mentioned above, a database platform is a complex system, and although improving one component may help alleviate a performance problem, it’s unlikely that 100% faster processors will provide a doubling in capacity, as it’s likely to move the bottleneck to a different point . This can make the TCO costs relatively expensive in the longer term.
- Need for Downtime: Hardware upgrades, especially on single node machines require downtime to complete which is often not desirable or even possible in some cases.
- Cost and effort to re-platform: A highly integrated data warehouse platform with multiple undocumented sources and downstream feeds could take months of planning, migrating and testing to migrate to a larger machine. Leaving aside the cost of new hardware, the migration can add a significant burden on an already over-stretched IT department. Even more so if it’s required again five years down the line.
The arguments for/against Scaling Out include:
- Ease of extension: A scale out solution implies a distributed system, and in many cases this can be easily extended with additional nodes to add capacity, often with zero downtime, and automatic node rebalancing. That’s certainly the case with many NoSQL databases including HBase and Cassandra.
- Limits of Scale: Despite vendor claims to the contrary, both Shared Disk and Shared Nothing architectures do (in most cases), have scalability limits. Depending upon the solution deployed, adding addition nodes may involve re-partitioning the data (not a small task).
- Need to re-architect: Depending upon the existing solution, it may be necessary to rework or re-architect the entire database. This can vary from a relatively straightforward migration from a single node database to a shared disk solution, or a complete migration to an entirely new database and hardware architecture, for example from single node Oracle to an MPP system from Vertica or Greenplum.
Conclusion
As in most aspects of IT, it’s important to start with a clear understanding of the problem, and separate the challenges of performance from the bigger, architectural requirement of scalability. Many would love to try out new technologies including NoSQL databases, but (as you’ll see in the next article), these do come with significant drawbacks, although admittedly with truly unlimited scalability.
If expected database growth is more organic, it may be more sensible to consider Scaling Up the existing hardware platform, although if you’re already running a MPP cluster or you’ve hit the hardware limits, then a Scale Out architecture may be more appropriate. Again you need to be aware of the potentially significant drawbacks.
The most obvious (but important) take-away however, is you can design and tune for performance, but once selected and installed, your options to scale have already been decided. Architect for scalability, and then design and tune for maximum performance.
About the Author
John Ryan is an experienced Data Warehouse architect, designer, developer and DBA. Specializing in Kimball dimensional design on multi-terabyte Oracle systems, he has over 30 years IT experience in a range of industries as diverse as Mobile Telephony and Investment Banking. This first appeared as an article in a series on Databases and Big Data. Follow him on LinkedIn for future articles.
Featured Resources



