
- Volt Active Data v6.0 extends existing capabilities and simplifies fast data application development with unparalleled performance, availability, and durability.
- Volt Active Data v6 introduces Geospatial SQL support, allowing applications to query spatial relationships between points and polygons for real-time analytics.
- Cross Datacenter Replication (XDCR) in Volt Active Data v6 enables geo-distributed databases with active/active replication, maintaining separate, active copies of the database in different locations.
- Volt Active Data v6 optimizes the fast data pipeline with built-in importers (e.g., Kafka) and a new export connector for Elasticsearch, streamlining data ingestion and enabling full-text searches.
- Volt Active Data v6 enhances SQL support with IN/EXISTS subqueries and additional column functions, along with performance improvements to the SQL execution engine and memory allocation.
TL;DR
Volt Active Data is already the go-to product for developing fast data applications because of its unparalleled performance, availability, and durability. v6.0 builds on that foundation by extending existing capabilities and simplifying the development process.
What does a Volt Active Data application look like? Some of the characteristics are:
- Applications ingest and process lots of data – data (events) being delivered at hundreds of thousands to millions per second. The workloads being thrown at these applications are write-heavy.
- Applications need to compute, track and display real-time analytics on live fast-arriving data. Real-time analytics include leaderboards, rankings, and sliding time-windowed rankings (past minute, past hour, past day, etc).
- Applications need to make per-event transactional decisions on live fast-arriving data, in just a few milliseconds. These decisions are often computed taking into account recent history, summaries (analytics) of recent history and OLAP analytic results.
Applications in the mobile, telco, Internet of Things (IoT), digital advertising and financial domains face these requirements every day, 24×7. It sounds like a challenging problem, and it is. And this is exactly the challenge that all Volt Active Data customers are solving today – with speed, simplicity and absolute accuracy – using the Volt Active Data in-memory database.
With Volt Active Data v6, we’ve extended these core capabilities. We’ve added Geospatial SQL support and integrated our new streaming importers into the clustered database itself, giving software developers the ability to, excuse the pun, streamline fast data application development. Volt Active Data v6 also introduces support for geographically distributed database replication, called Cross Datacenter Replication (XDCR). Interested in the details? Read on. Heard enough and want to try it out? Download it here.
Must Read: Real-Time Data Pipeline
Geospatial Applications with Real-time Analytics
Geospatial applications deal with polygons, a set of latitude/longitude points that define a region (perhaps the boundary of a shopping mall, a sports arena, or a neighborhood or city), and points, which are a latitude/longitude pair defining a specific location (of, say, a person or device). Volt Active Data SQL now supports two new datatypes to represent polygons and points: GEOGRAPHY and GEOGRAPHY_POINT. But points and polygons are not very valuable without the ability to query on the relationships between them, such as contains or distance. As such, Volt Active Data v6 has added a set of geospatial column functions, including CONTAINS, DISTANCE, and AREA among others.
What does a fast data geospatial application look like? Imagine a fleet of taxis that need to coordinate where to be after concerts and sporting events finish up. The application tracks tens of thousands of taxis for millions of customers across the country. To meet demand, drivers can be directed to the location of events containing large numbers of potential customers. By way of a concrete example, this SQL query would give a count of attendees within the vicinity of each public venue:
| SELECT pp.name AS place_name, COUNT(*) AS attendee_count | |
| FROM attendees AS a | |
| INNER JOIN public_places AS pp | |
| ON CONTAINS(pp.border, a.loc) | |
| GROUP BY pp.name | |
| ORDER BY attendee_count DESC | |
| LIMIT 3 | |
| place_name attendee_count | |
| ——————- ————– | |
| TD Banknorth Garden 786 | |
| Fenway Park 512 | |
| Agganis Arena 413 |
view rawgistfile1.txt hosted with ❤ by GitHub
To complete the scenario, coupons or personalized offers could be delivered to each customer at each event, prompting new “in the moment” transactions.
In the smart grid (Internet of Things) market, consider this real-time analytic computation for an electric smart meter grid. The result of the query captures the number of kilowatts (as an instantaneous measurement) being consumed in a neighborhood divided by the area of the neighborhood. In other words, the real-time analytic is the density of the electricity consumed for a given set of regions at a discrete point in time:
| SELECT | |
| n.name AS neighborhood_name, | |
| SUM(m.kw) / AREA(r.border) AS kw_per_m2 | |
| FROM neighborhoods AS n | |
| INNER JOIN meters AS m | |
| ON CONTAINS(n.border, m.loc) | |
| ORDER BY kw_per_m2 DESC | |
| LIMIT 3 | |
| neighborhood_name kw_per_m2 | |
| —————– ——— | |
| Pawtucketville 1247.79 | |
| Belvidere 1004.37 | |
| Highlands 998.0 |
view rawgistfile1.txt hosted with ❤ by GitHub
In this query, we’ve used CONTAINS as a join predicate, which allows us to generate the neighborhood groupings.
With the addition of these two new geography data types along with a set of geospatial column functions, Volt Active Data v6 delivers the core capabilities for building fast data geospatial applications.
Geo-Distributed Databases with Volt Active Data Cross Datacenter Replication (XDCR)
Volt Active Data Database Replication got a major upgrade with the v6.0 release. Earlier in the year we released our new passive database replication feature, parallel binary replication between the master and replica clusters. With the v6.0 release we’ve added cross datacenter replication (XDCR). XDCR is bidirectional database replication, also called active/active replication.
XDCR allows you to maintain separate, active copies of the database in two separate locations. For example, XDCR allows you to maintain copies of a telco accounts/billing database at two separate locations, making it possible to support interactions that might result in unacceptable latency when the database and the users are geographically separated.
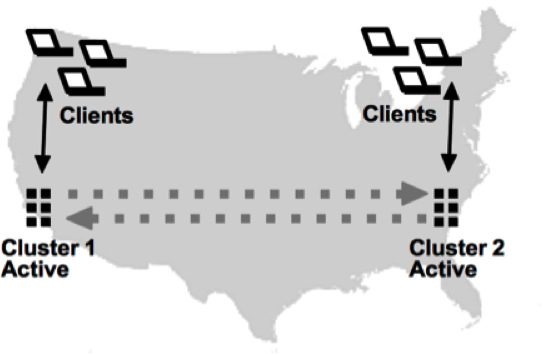
As with active/passive replication, the transactions are committed locally, then asynchronously applied to the other database. So when using XDCR to maintain two active clusters you must be careful to design your applications to avoid possible conflicts when transactions change the same record in the two databases at approximately the same time.
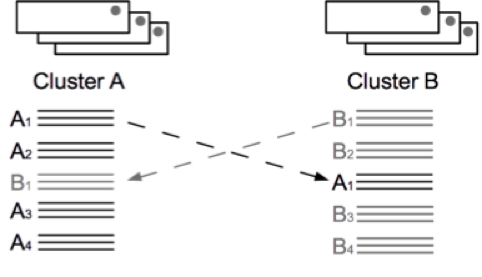
If such a situation does occur, Volt Active Data will detect a conflict, log it, and apply a default conflict resolution policy in an effort to keep both databases consistent. For more details on conflict resolution in Volt Active Data, please see the Using Volt Active Data chapter on Understanding Conflict Resolution.
Fast Data Pipeline
Volt Active Data offers a set of import and export integrations, all designed to help you ingest streaming data, process it within Volt Active Data, and, once the data is no longer immediately valuable, export data seamlessly to a historical data warehouse.
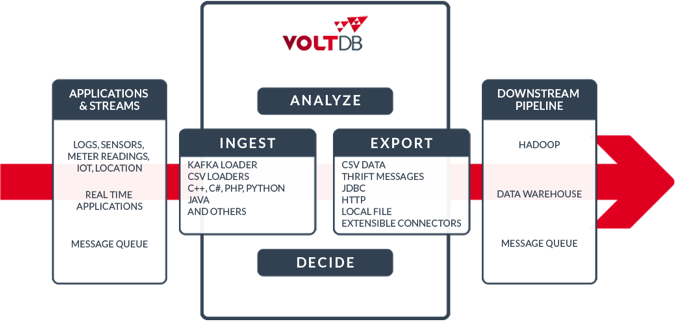
In previous releases of Volt Active Data you were able to load as well as stream data into Volt Active Data by using a supplied external loader application (the Kafka Loader and the JDBC Loader for example). This streaming import strategy required an additional process, and thus an additional network hop, and also required the developer to devise a high availability strategy for the import process. With Volt Active Data v6 the front-end of the pipeline has been optimized with the release of built-in importers.
Built-in importers work similarly to the data loaders, where incoming data is written into one or more database tables using an existing stored procedure. The difference is that the built-in importers start automatically whenever the database starts, and stop when the database stops. They are part of the database process. As such, they can be highly available much as the database is.
One of the first importers we’ve released is for Kafka. Kafka is a high-throughput, low-latency platform for handling real-time data feeds. The Kafka importer makes it easy for Volt Active Data to ingest streams of data from Kafka message queues. The Kafka importer connects to the specified Kafka messaging service and imports one or more Kafka topics inserting the records into the database automatically or via a call to a user-specified stored procedure. As with our export connector, It is also possible to easily create your own custom importer.
In addition to built-in Importers, Volt Active Data v6 includes a new export connector for Elasticsearch. Elasticsearch is an open-source full-text search engine built on top of Apache Lucene™. By exporting selected tables from your Volt Active Data database to Elasticsearch you can perform extensive full-text searches on the data not possible with Volt Active Data alone.
Finally, we’ve expanded the capabilities of both Import and Export processing by supporting importing from multiple feeds of different types as well as exporting to multiple different downstream targets.
Expanded SQL support
With each iterative release of the Volt Active Data database we enhance the capabilities and performance of our SQL engine. In addition to the geospatial SQL described earlier, Volt Active Data now supports SQL IN/EXISTS subqueries as well as a host of additional column functions, including:
DATEADD, REGEXP_POSITION, PI, LN, MOD, BITAND, BITOR, BITXOR, BITNOT, BIT_SHIFT_LEFT, BIT_SHIFT_RIGHT, HEX, and APPROX_COUNT_DISTINCT.
In addition to the new SQL language constructs, we’ve also made numerous performance enhancements to our SQL execution engine. Additionally, we’ve reduced the memory allocation needs for string storage and also when executing complex queries. And we’ve improved the efficiency of views and index handling.
Volt Active Data Management Center (VMC)
In early 2015 we introduced our web-based Volt Active Data Management Center and throughout the past year we regularly enhanced it. With the VMC you can manage and monitor your Volt Active Data database. You can even manage and monitor Volt Active Data database replication.
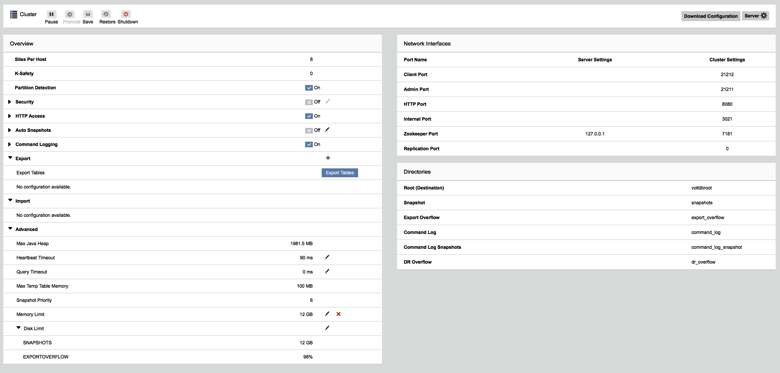
Enhancements to VMC over the past year include the addition of cluster administration, giving you the ability to view as well as change cluster settings on active databases as well as databases running replication, including XDCR.
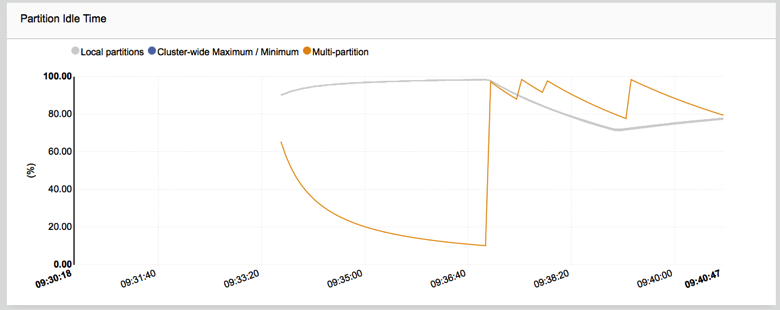
New monitoring graphs let you monitor the status of Volt Active Data durability (Command Logging disk i/o) as well as workload balance through the new Partition Idle Time graph (seen below).
To invoke the VMC, simply point your browser to any node in the Volt Active Data cluster, port 8080, as follows: http:// voltserver:8080/.
Other Features of Note
There are many other features that we’ve added to Volt Active Data that aren’t major, but deserve noting. Volt Active Data now supports rack-aware partitioning, allowing you to specify how partitioned data is placed across your cluster’s machines, helpful for tuning high availability on server racks or VM farm machines. We’ve also added the ability to create and restore per-table snapshots, an often requested feature. The Volt Active Data database now supports per-query timeouts and will also automatically switch the database into read-onlymode when a memory usage threshold is reached or when disk-durability cannot be maintained due to drive hardware failure.
The theme for the Volt Active Data v6.0 release is geo-distributed fast data, and we’re pretty excited about the types of applications that v6 enables. Our new geospatial SQL support, coupled with cross datacenter replication, provides a transactional low latency/high throughput database foundation for today’s emerging globally-oriented fast data applications.
Whether you view your application as a transactional application with real-time analysis or as a stream processing engine that requires per-event decisions, Volt Active Data is the only system that combines ingestion, speed, robustness and strong consistency to make developing and deploying your fast data applications easier than ever – take a look at the MaxCDN and Emagine case studies for examples of how Volt Active Data provides better application development outcomes, more simply, faster and reliably.
Download Volt Active Data 6.0 here and give it a try. We’d love your feedback, feel free to send us a note at info@voltactivedata.com.
About Author

Featured Resources



