Combine Stateless Stream Processing With OLTP
Integrate real-time stream processing with stateful transactional workflows to fully leverage the potential of your streaming data.
OLTP does streaming, but it’s very slow. Streaming does some OLTP, but not all of it.
Volt(SP) lets you address stream processing and OLTP in the same place via a single, unified platform that complements existing systems.
Stateful and Stateless Processing with One Platform
By combining stateless stream processing with stateful transactional processing, Volt(SP) offers a solution to enterprises needing to make fast, contextually intelligent decisions on data from multiple sources. Designed to complement common streaming solutions, Volt(SP) is especially suited to any enterprise with systems or applications struggling with complexity or latency SLAs.
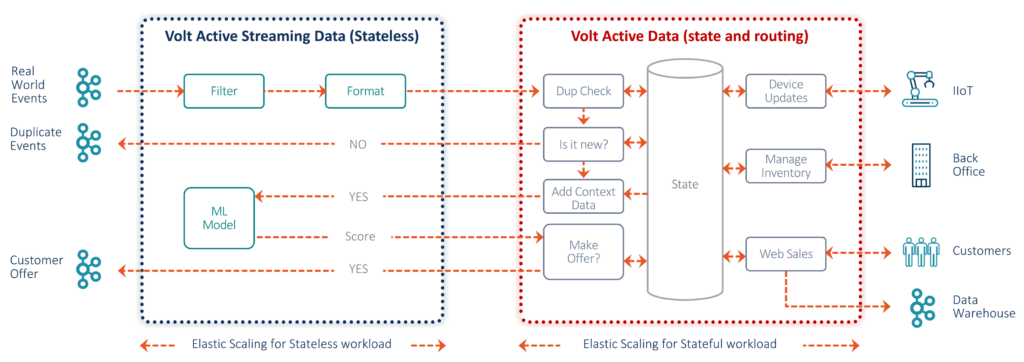
Make Low-Latency Stream Processing Easy and Affordable
The volume and complexity of event-based data entering systems makes it essential to stay up-to-date, as falling behind can quickly become unmanageable.
Simply put: If you can’t keep up with your data, your systems will go down, and so will your applications.
Volt is the only data platform purpose-built to enable scalable, stateful, low-latency processing of streaming data without compromising on resiliency, consistency, accuracy, or TCO.
Featured Assets
Solution Brief
Volt + Kafka for Solution Architects
Evolve from ‘moving data at scale’ to making real-time decisions on increasingly complex data streams. Kafka is a powerful messaging queue that has become a core component of many enterprises’…

Technical Paper
How to Take Full Advantage of Your Streaming Data
Thanks to 5G, IoT, and their related technologies, being able to manage streaming data at scale and without breaking the bank in infrastructure costs has become critical for the success…
Technical Paper
Volt Active Data’s Top-10 Capabilities
Volt Active Data is the leading data platform designed to power real-time telco and other applications that must dynamically react in single-digit milliseconds to drive revenue and prevent revenue loss….